
Delta Lakes 101: how to organize Big Data in object storages
While working with Big Data, they are many obstacles that must be surpassed to achieve good results, that are not present in cases with smaller data involved.
From all the information that I have, which is the relevant one?
How can I obtain the insights required in an efficient way?
Which services or tools do I need to use in order to get these results?
Those quests are just some examples of an ocean of doubts that the data roles have to face in these situations, and need to be solved at some point. Nevertheless, there is another question that may be not as obvious as the previous ones mentioned, but is critical to build a solid base for all the data operations of the company:
How can I store the data?
In medium and small sized data, this decision is not that important because relocating or transforming the data is something easy to do if needed. In contrast, with data sources that have several millions of rows, it is key to follow a proper path from the beginning because corrections in the structure can be not affordable in terms of time and resources.
In this post, we'll introduce you to Delta Lake, a game changer for such scenarios. We'll explore how Delta Lake can help in efficiently storing, managing, and querying Big Data, using a real case to illustrate these operations.
1. Let's present a real case
In recent times, analysis have shown that the prices of basic supermarket products in Spain are on the rise. Many businesses want to monitor these trends closely, and one such approach is by capturing the daily prices of products across different supermarkets.
Imagine a company that does precisely this. Every day, they collect data on various product prices from multiple supermarkets. Over time, this process results in vast amounts of data — we're talking about tables with millions of rows, each updated and modified frequently. Managing such a large volume of data presents the challenge we mentioned early. In order to simulate it, we are going to use the supermarket products dataset provided by DataMarket, that have been used in several reports and studies from relevant entities in Spain like El País or RTVE.
| Name | Type | Description | Example |
|---|---|---|---|
| category | str | Product category. | marisco_y_pescado_pescado_congelado |
| description | str | Additional product information (packaging format, etc.). | Pack-2 |
| insert_date | datetime | Date of information extraction. | 2020-09-23 14:15:00 |
| name | str | Product name. | Anguriñas de surimi Pescanova |
| price | float | Absolute product price. If there is any discount, the lowest price appears. | 1.99 |
| reference_price | float | Unit price (per product unit of measure, €/Kg, €/L, etc.). | 7.96 |
| reference_unit | str | Product reference unit (Kg, L, etc.). | kg |
| supermarket | str | Supermarket the product belongs to. | 433463D95980C252B92C204E3655BB81 |
In the example, the data processing will be done using PySpark, the main tool when talking about Big Data processing. Additionally, a unique id column called record_id has been created, in order to make the processing easier.
2. How can we store Big Data?
This is not a question with a single answer. There are many solutions provided by different companies and open source projects, both on-premise and cloud-based. However, the majority of the traditional approaches suitable for Big Data can be classified in two groups:
Data Warehouses: this storage solution is a specialized type of database that has been optimized to deal with Big Data. Data Warehouses are prepared to run complex queries against huge datasets, in order to provide insights to analysts. In order to be stored there, the data captured needs to be structured and fit the schema established by the table, which is a limitation but also acts as a quality control. Besides, the deployment of this kind of solution tends to be more expensive, due to the requirement of specific software from the cloud provider or powerful resources.
Data Lakes: this approach lies in the usage of an object storage (like Amazon S3 or Google Cloud Storage) to keep the data. The price of this solution is quite low, specially when compared the Data Warehouses, and it is flexible to store any type of data in the same place (structured, unstructured, images, video, etc.) acting as a centralized repository. However, without default quality control, improperly managed ingestion and ETL processes can turn a Data Lake into a Data Swamp.
Both approaches have their own advantages and disadvantages, which determined the proper solution in each specific use case. Nevertheless, as always, there are people who want it all, and tried to develop a hybrid software that allow the users to obtain the benefits of Data Warehouses and Data Lakes at the same time, creating a new solution: the Data Lakehouses.

A Data Lakehouse is based in the idea of taking a basic and cheap storage such as a Data Lake, where all the data sources can be centralized, and use an extra software to provide the Data Warehouse features only to the specific sources that are suitable for them. Thanks to that, it is possible to get cheap prices and general flexibility at the same time the structured data sources are kept clean and controlled. And one of the magic tools that aims to achieve that is the main character of this post: Delta Lake.
3. Let's get started
After the fundamentals, lets apply it to our example. The company has been capturing and uploading the data in Parquet till the point that the table has reached several million rows, and they have decided to migrate it to a delta lake.
3.1 Installation and setup
As it was mentioned before, this tool will be used alongside PySpark through the Python API, delta-spark. Both of them can be installed using pip:
pip install pyspark pip install delta-spark
It is also necessary to ensure that the installed version of PySpark is suitable for working with the selected version of Delta Lake. Now in Python, the Spark session is configured to integrate Delta Lake:
# required imports...
from pyspark.sql import SparkSession, functions as f
from delta import configure_spark_with_delta_pip, DeltaTable
# creating pyspark builder...
builder = (
SparkSession.builder.appName("wb_delta")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config(
"spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog"
)
)
# creating pyspark session...
spark = configure_spark_with_delta_pip(builder).getOrCreate()After doing this, it is possible to create and interact with delta lakes directly using PySpark.
3.2 Creating a Lakehouse
I have talked about the advantages of Data Lakehouses, and it has been mentioned the possibility to create one using a Delta Lake. However, what is exactly a Delta Lake? This concept has two different dimensions:
From the point of view of the data, the delta format uses Parquet but introduces an extra component: a transactions log that registers all the changes that the data suffers. It is saved in json format.
From the point of view of the software, the delta lake framework is able to read not only the data in Parquet, but also the transaction log. That information is used to introduce some extra features that the Spark engine does not allow by default, including ACID transactions, time travel, DML operations and schema evolution. This required software is set in the spark session through the configuration shown before.
Then, if the data is originally saved in Parquet, it is possible to just switch the storage format to delta using the spark session created. In the following example, a delta lake with a sample of the data:
RAW_DATA_PATH = "path/to/raw/data"
LAKEHOUSE_PATH = "path/to/delta/lake"
# reading the raw data in parquet...
sdf_raw = (
spark.read.parquet(RAW_DATA_PATH)
.select([f.monotonically_increasing_id().alias("record_id"), "*"]) # record id column creation
.alias("sourceData")
)
# saving the raw data as a delta lake...
(
sdf_raw.sample(0.5)
.write.format("delta")
.mode("overwrite")
.partitionBy("supermarket") # this column is used as a partition to increase efficiency
.save(LAKEHOUSE_PATH)
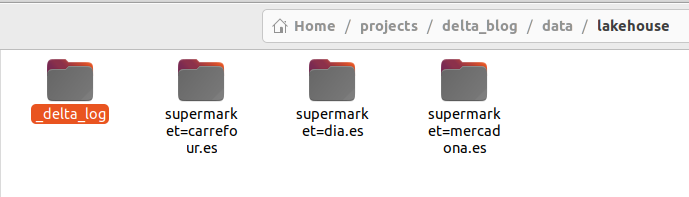
)In the following picture, it can be seen the structure of the generated delta lake. The .json logs are stored in the _delta_log folder, and the data is saved in Parquet just like in the original case.
dl = DeltaTable.forPath(spark, LAKEHOUSE_PATH).alias("deltaTable")
dl.history()| version | timestamp | userId | userName | operation | operationParameters | job | notebook | clusterId | readVersion | isolationLevel | isBlindAppend | operationMetrics | userMetadata | engineInfo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-10-27 10:44:... | null | null | WRITE | {mode -> Overwrit... | null | null | null | null | Serializable | false | {numFiles -> 5, n... | null | Apache-Spark/3.4.... |
As it can be seen, the transaction log stores all the information related to each of the operations performed over the delta lake, in order to track how the content is evolving over time.
3.3 Operations in a Delta Lake
By default, the basic operations that can be done with PySpark are strongly limited. It can be used to read data from different sources, filter it, perform some ETL and save the results to a location. It lacks advanced features such as ACID transactions. Consequently, in the event of an issue during the data-saving process, there is a significant likelihood that the entire operation could abruptly stop, potentially leading to disruptions in the integrity of the original dataset. Besides, without creating external and complex logic, it is not possible to limit the computations over the data that is new in the dataset or meet certain conditions.

This is a drawback that can be surpassed using Delta Lakes. The tool provides the possibility of performing Insert, Delete, Update and Merge operations like a normal database, following the ACID properties and improving the data integrity. Going back to the supermarket products data, this functionality can be used to insert rows in the lakehouse only if they are not registered yet:
(dl.merge(
sdf_raw,
f"deltaTable.record_id = sourceData.record_id" # condition for the upsert
)
.whenNotMatchedInsertAll().execute())The merge is referenced in the log file as well:
| version | timestamp | userId | userName | operation | operationParameters | job | notebook | clusterId | readVersion | isolationLevel | isBlindAppend | operationMetrics | userMetadata | engineInfo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2023-10-27 13:44:... | null | null | MERGE | {predicate -> ["(... | null | null | null | 0 | Serializable | false | {numTargetRowsCop... | null | Apache-Spark/3.4.... |
| 0 | 2023-10-27 10:44:... | null | null | WRITE | {mode -> Overwrit... | null | null | null | null | Serializable | false | {numFiles -> 5, n... | null | Apache-Spark/3.4.... |
Executing this task without Delta Lake is possible, but it's much smoother with it. Moreover, the advantages escalate when the data to be inserted originates from a complex processing stage. During the insert/update/merge operations, this tool smartly minimizes the number of operations required. It applies the ETL processes solely to the new data being added to the table, leaving the rest untouched, which in turn saves both time and operational costs.
3.4 Time travel
"Roads? Where we're going, we don't need roads. 🚙🔥" - Dr. Emmett Brown
Despite we do our best to ensure that everything goes well, failures are sometimes unavoidable. It is not very rare while performing ETLs to make a mistake and generate an output with errors. And, while working with Big Data, the consequences may be quite expensive.
In order to avoid these situations, Delta Lake provides a version control of the data. Every time an operation is performed, a new version is created, adding new Parquet files with the new data inserted. In our example, the merge performed has created a version 1, but it is possible to read the version 0 directly with spark:
spark.read.format("delta").option("versionAsOf", "0").load(LAKEHOUSE_PATH)
or to create a new version copying this one:
dl.restoreToVersion(0)
This feature is highly effective for bug prevention; however, it's important to be mindful of potential data redundancy issues when storing all versions of the data. This can result in elevated storage costs. To mitigate this, Delta Lakes introduces the vacuum method, which helps manage data redundancy by removing older versions based on a "retention hours" parameter. Any versions created prior to this specified time frame are automatically deleted. In hour example:
dl.vacuum(retentionHours=RETENTION_HOURS)
Note: by default, the retention hours are equivalent to 7 days and the possibility of reducing it is limited. Nevertheless, it is possible to introduce smaller number of hours setting this option in the Spark session:
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")3.5 Optimizing performance
In the realm of Big Data solutions, computing times often scale up significantly due to the immense number of operations that need to be executed. For that reason, it is key to optimize every process in order to steer clear of unnecessary computations, as these can be translated into substantial delays with tangible consequences. And, from that side, Delta Lake also offers methods to contribute in this optimization effort.
On the one hand, the layout is relevant. If each partition contains a high number of small-sized Parquet files, there may be an impact in query performance. This scenario often arises in cases similar to our supermarket data example, where data is regularly ingested, and each merge operation generates new Parquet files. To solve this problem, Delta Lake includes the optimize() method, that creates a new version of the table but compressing the files in each partition in just one. In the example, it would be done through the following code:
# to optimize the entire table...
dl.optimize().executeCompaction()
# to optimize just an specific partition...
dl.optimize().where("supermarket='dia.es'").executeCompaction()This is not the only solution that Delta Lake offers for performance optimization, it is worth to mention another concept: data skipping. By default, this tool collects basic statistics (such as min and max values) of the columns, and use them to improve the querying speed. By default, this feature is limited and only applies for the first 32 columns, due to the fact that the computational cost of it for some long column types (such as string or binary) can be higher. However, this behavior can be adjusted using the delta.dataSkippingNumIndexedCols property:
spark.conf.set("spark.databricks.delta.dataSkippingNumIndexedCols", "34")The data skipping feature is activated automatically, but in order to fully exploit its capabilities, it is recommended to also apply another optimization method provided by Delta Lake: the Z Ordering. This technique involves sorting the rows inside each file according to the values of one or more selected columns, reducing the amount of data that needs to be read in each operation. Like the optimize technique, this feature requires the execution of a method:
# to optimize the entire table...
dl.optimize().executeZOrderBy(["insert_date"])
# to optimize just an specific partition...
dl.optimize().where("supermarket='dia.es'").executeZOrderBy(["insert_date"])All these techniques are very powerful for performance optimization but should be used with careful consideration:
"Remember, with great power comes great responsibility. 🕷️" - Uncle Ben
These features also involve some calculations to apply. If you have a lot of data, it's not necessary to use them after every data change. Instead, you should apply them periodically based on the needs of your specific business case.
3.6 Be careful with concurrency
Managing data becomes quite tricky when multiple processes need to work with it simultaneously. When using only Spark, it can be problematic because if one process is editing the data while another tries to read it at the same time, the second one is likely to crash or run into issues.
From that point of view, Delta Lake also improve the default capabilities. When a process reads data, it accesses the most recent version available at the time of loading. Consequently, if changes are made to the table, a new version is generated, leaving the original version stable for the process that's already reading it. This means readers don't impede writers, and vice versa, a behavior known as optimistic concurrency control. In essence, Delta Lake enables smoother concurrent data access without causing crashes or conflicts between readers and writers.
However, it is important to note that this solution is not flawless, and errors can still arise when two processes attempt to write data simultaneously. When conflicting information is inserted concurrently, the system cannot always determine the correct order, leading to concurrency errors. One way to reduce these issues is to make sure that concurrent processes work in different data partitions, isolating the files they modify. The table below illustrates which concurrent operations can potentially result in failures:
| INSERT | UPDATE, DELETE, MERGE INTO | COMPACTION | |
|---|---|---|---|
| INSERT | ✅ | ||
| UPDATE, DELETE, MERGE INTO | ⭕ | ⭕ | |
| COMPACTION | ✅ | ⭕ | ⭕ |
Another problematic situation that could arise is when a process is reading an old version of the data, which could be deleted by a vacuum operation. This is an infrequent occurrence since the usual retention hour parameters are set at a level high enough to prevent such situations.
4. To sum up
In essence, Delta Lake offers significant advantages for handling Big Data efficiently:
Data Integrity: Delta Lake ensures data consistency with ACID transactions, guaranteeing reliability in complex operations.
Time Travel: It allows you to access previous data versions, aiding auditing and data correctness.
DML Operations: Delta Lake supports data manipulation operations like inserts, updates, and deletes, giving you data control.
Performance Boost: It optimizes performance with compaction and data skipping, speeding up data processing.
Concurrency Control: Multiple users can read and write data concurrently without conflicts, enhancing collaboration.